NO EXECUTE!
On the topic of Windows 8 in general, a couple of useful keystrokes I forgot to mention in the last post which are applicable both to Windows 8 and the new Windows 8.1: Windows+X brings up the shortcuts menu to useful things such as Control Panel and Administrator Command Prompt. Ctrl+Tab lets you toggle between the Start screen and the Apps screen, i.e. move between your tiles and your program icons. Learn them, they are your friends.
Back to Haswell, I recently built myself a new Haswell based system and have been putting it through its paces; double-checking that all the features I've been expecting in Haswell are actually there (and they are!). Today I'll give you an overview of some of Haswell's great new features, and explain why the armchair critics are missing the point if they think Haswell merely represents a few percentage point performance increase over Ivy Bridge.
Before I look at some of the other events from this past year I have to give my usual full disclosure disclaimer that I do own stock in Amazon, Intel, and Microsoft whose products I mention in this posting.
ARM and Atom soon to be outperforming Pentium 4 and PowerMacs (in more ways than one)
While Haswell represents the latest in a long line of "big cores" which deliver maximum bang per clock cycle (i.e., a high IPC rate, instructions per cycle), there has been a lot of recent activity at the other end of the spectrum with the power-efficient "small cores", namely ARM and Intel Atom, which aim to deliver best battery life. The diversity of ARM-based products is exploding just as I anticipated. Just three years ago I started discussing ARM in this blog, how there would soon be a wave of ARM-based tablet devices, and how potentially using QEMU (or a similar emulator) could be used to provide low-cost low-power x86 alternatives for running mainstream software. That future is now here, with devices such as a the Microsoft Surface RT bringing Windows 8.x and even Office 2013 to the ARM platform, and the Google Chromebook giving users a fully unlocked ARM-based Linux machine, and already ARM is biting into the cloud server space, such as HP's recent Project Moonshot(http://www.theregister.co.uk/2011/11/01/hp_redstone_calxeda_servers/).
I own both the Surface RT and the Chromebook and last month took both with me on my summer vacation to Europe. Specifically, I only took ARM-based devices. For the first time in almost 20 years of travelling overseas with a computer of some sorts, I did not take an x86 device with me - not my Dell laptop, not my Sony VAIO, not even an Atom netbook. I survived for two weeks on just those two devices running Windows 8.1 RT Preview and Ubuntu Linux respectively. With the ubiquity of wi-fi hotspots these days, even wi-fi at 35000 feet on Delta, it was also my most connected vacation, practically being online as much as when at home. Which is good, since most apps on both the Surface RT and Chromebook really need an internet connection to be useful.
I was surprised to be able to function almost normally with those two machines despite not having a traditional laptop with me. I used the Surface RT for Facebook, to play Angry Birds Star Wars, and do my email (and with Outlook 2013 now built-in to the Windows 8.1 Preview, have the same email experience on the desktop). The Chromebook was more my web surfing machine, lacking the touch screen but making up for it with the full sized keyboard. One thing I learned about a touch device such as the Surface RT or iPad, it's harder to use the one-screen keyboard in your lap (such as on a cramped airplane seat). You really still need a clamshell type notebook device to be able to type well in your lap, because prop it up as you might a touch screen just shakes too much when it's not on a solid footing.
For a few days this ARM-only setup was great, taking two light ARM devices which complemented each was much easier than lugging my much larger and heavier Sony VAIO laptop. In this respect, ARM devices are almost on par with regular "big core" based laptops, and certainly run circles around the miserable Pentium 4 laptops of just 10 years ago in terms of weight, cost, and battery life. The kinds of things you did on your bulky hot $3000 laptop 10 years ago - Outlook, PowerPoint, web surfing, image editing - you can do today on a light small $249 to $399 device. This is a milestone that Intel Atom based netbooks started to achieve starting in about 2008 and will most certainly surpass with the latest generation of 2013 out-of-order core Atom processors.
Just this past week, I purchased another ARM device - the new Nokia Lumia 1020 phone to upgrade my much older cell phone. It wasn't released until I was already in Europe but boy I wish I'd had it with me. The 40+ megapixel camera is great, just point and shoot at anything and then worry later about actually zooming in and cropping the picture. The image editing software rivals what you'd be running on your huge Power Macintosh or Pentium 4 box a decade ago. So in that respect, the portability of ARM devices has given us the features that we had on our huge desktop workstations and moved that to our hands.
A more surprising observation is that today's ARM devices are set to outperform desktop Pentium 4 processors of 10 years ago. Like others have also done and reproduced in the past few months, I trivially recompiled the Bochs 2.6.2 simulator to host on ARM, using both Visual Studio 2012 for ARM to run on Windows RT, and using Ubuntu's gcc 4.7.3 for ARM on the Chromebook. I was pleasantly surprised to see Bochs booting and running relatively fast on ARM - taking Bochs 2.6.2 on ARM roughly 4 minutes to boot up my standard Windows XP disk image on the 1.7 GHz Chromebook compared to a little over 3 minutes on my 2002 era Dell WS650 workstation (based on the 2.0 GHz Pentium 4 Xeon, Intel's top of the line chip that year). Steady state performance is also higher, hitting almost 50 MIPS on ARM, comparable to the rates I see on the same Bochs version built for an Atom host or my PowerPC G5 machine running Fedora Linux. The Xeon has the benefit of a slightly faster 2.0 GHz clock speed and delivers a peak of 55 MIPS, so clock cycle for clock cycle, Bochs shows that ARM is getting close to outperforming Pentium 4. It already outperforms the PowerPC G5, as the G5 build on Fedora only maxes out at about 40 MIPS.
Don't the Pentium 4 and G5 run at much faster clock speeds you ask? Peak CPU performance is one thing but it should be noted that in terms of other factors such as memory size, memory bandwidth, disk size, disk performance, and video performance, today's mobile devices already outperform Pentium 4 and even PowerPC G4 and G5 desktop systems from ten years ago. One reason Bochs on ARM is able to outperform the same build on PowerPC is the vastly faster memory bandwidth of today's devices, while the PowerPC and Pentium 4 and even Atom were stuck at what is now miserable bandwidth of about a gigabyte a second. Clock speed alone can't compensate for such a memory bottleneck. What can I say, the progress of miniaturization is amazing!
Xformer on ARM
Another proof of concept I tried last year was to port my Xformer emulator to ARM (Xformer is the Apple II and Atari 800 emulator I original wrote in 1986, and the Atari 800 emulating portion of Gemulator). Ironically back in 1986, Ignac Kolenko and I originally wrote our 6502 interpreter engine in Megamax C on the Atari ST. The performance wasn't great, as C compilers weren't the highly optimizing compilers that they are today, so in late 1986 and early 1987 I hand coded the 3000 lines or so of 6502 interpreter from C to 68000 assembly language in order to achieve the roughly 1 MHz 6502 emulation speed on an 8 MHz 68000 host that was needed to give decent Apple II and Atari 800 emulation performance. I turned my work into a two-part article in ST LOG magazine later in 1987, describing all the hoops and hurdles that my assembly code jumped through to hit that performance level, worth a read for anyone interested here: http://www.atarimagazines.com/st-log/issue18/71_1_INSIDE_THE_ST_XFORMER.php. Later on in 1990 when I owner my first 80386 based MS-DOS computer, I translated the 68000 hand code in 80286 assembly code for 16-bit MS-DOS, and then years later converted that code to proper 32-bit 80386 code to run on Windows 95 and XP. You can download and look at that code in the open source Gemulator 9 release I made back in 2008.
So faced with now yet another rewrite for ARM, I was not so keen to crank out thousands more lines of ARM assembly code. In fact, given that I've spent the past year working on the compiler back end, it seemed proper to put my money where my mouth is and stop implementing interpreter loops in assembly. After all, my own work on optimizing Bochs in C++, my work on a C++ based microcode simulator (http://amas-bt.ece.utexas.edu/2011proceedings/amasbt2011-p3.pdf), and my various blog postings on lazy flags techniques for C/C++, this was a perfect opportunity to sanity check that C/C++ can in fact rival assembly code these days.
And so over a couple of weekends I rewrote the 3800 lines of x6502.asm from the Gemulator 9 release into about 3000 lines of x6502.c and built side-by-side x86 versions of Xformer, one built using the original assembly code in x6502.asm and one built using the C code in x6502.c. Much as I had done in Bochs five years ago, I replaced the x86-specific arithmetic flags manipulation code in the assembly to the lazy flags sequences that I've been writing about. Risky, because this increased the code size of the code sequences and involves more memory operations overall. But to my relief, this quick and dirty rewrite executed roughly 30% slower in C than the assembly version. With a bit of fine tuning using PGO (profile guided optimizations) in the Visual Studio compiler, I was able to bring that overhead down to under 20%.
This was a fantastic result. Without using any inline assembly code, or even any x86 intrinsics, I was able to get to within 20% of my best hand coded effort. There are reasons compilers can do this today compared to 20 or 30 years ago. Obviously compiler optimizers are better today. But also the availability of register calling conventions, auto-inlining by the compilers, and even custom calling conventions generated when using PGO results in code that's similar to the kind of code an assembly programmer would generate (e.g. use a known empty register to pass a parameter instead of following the standard C calling convention, inline memory copies, etc.). PGO also gives you the benefit of code layout that's optimized for the training scenario, so whereas in assembly code I have to consciously think about the relative placement of related code blocks for a common use case, the compiler and linker now do that for you.
So now, once I had my assembly-free C-only version of Xformer, I was able to trivially recompile for not only 64-bit mode, but also for ARM and run it on my Surface RT. As expected the 64-bit build was a tad faster thanks to the availability of more registers. But more surprising, the 32-bit ARM build on the Surface RT slightly outperformed my 32-bit Atom system by about 10%, or in other words almost matching my best x86 assembly code. Factoring in clock cycle difference (1.3 GHz ARM vs. 1.6 GHz on the Atom), ARM was in fact faster.
See here is where ARM systems today have an advantage over the Atom and over 32-bit x86 in general: Atom is stuck with the miserable memory bandwidth limitations and with the 8 register limitation of 32-bit x86. Meanwhile ARM has the benefit of 16 registers, slightly denser instruction encoding (which puts less pressure on the decoder and L1 code cache), and has register calling convention on by default. So at the same clock speed today's ARM processors will usually outperform today's Atom at identical compiled C/C++ integer code.
Gemulator and SoftMac port to ARM and x64
So naturally with this encouraging experiment with Xformer and Bochs builds on ARM, I've started my most ambitious project yet - a full port of Gemulator and SoftMac's 68040 interpreter engine to C++ - so that I can retarget these emulators to 64-bit systems and mobile devices. This port involves rewriting well over 10000 lines of hand coded assembly, and if you've looked at the Gemulator 9 assembly code, my obsessive use of macro expansions really means closer to about 100000 assembly instructions are being ported over. I don't expect to be done for many more months, but stay tuned.
Small cores powering the cloud
With 64-bit ARM on the horizon for next year (http://www.eetimes.com/document.asp?doc_id=1260488) small cores will indeed surpass the Pentium 4 as well as the PowerPC G5 itself in raw performance, and presumably eventually in clock speed. For emulation and virtualization purposes a 64-bit host is preferable, not only for the wider registers of course but also for the larger address space which makes address translation easier (I've discussed the details of this earlier postings). While my Bochs experiment was strictly a proof of concept using interpretation only and did not use any form of binary translation, I have no doubt that 64-bit ARM based servers will be able to convincingly host x86 workloads in the next year or two. Cloud is all about server density and power consumption, and small cores mean more compute power with less cooling required.
Atom is not down for the count though by any means. After 5 years of the current Atom architecture remaining relatively unchanged (what was effectively a huge die-shrink of the original Intel Pentium in-order core), Intel is set to unveil a whole new Atom with out-of-order pipeline calledSilvermont (http://newsroom.intel.com/community/intel_newsroom/blog/2013/05/06/intel-launches-low-power-high-performance-silvermont-microarchitecture). Silvermont according to Intel will deliver 3x the performance of the current Atom, which effectively means the IPC performance of a Core 2. The baseline performance of mobile devices with then effectively be raised from the level of Pentium 4 that we see today to that of a Core 2 laptop from only a few years ago.
I am being proven right about AMD
Two years ago while attending the AMD Fusion developer's conference here in Bellevue, I speculated about AMD's possible move to other CPU architectures in my posting (http://www.emulators.com/docs/nx34_2011_avx.htm#Bulldozer) as AMD seemed to be de-emphasing x86 in their talks about the "Core Next" and even surprisingly had someone from ARM giving a keynote. We now know that AMD is in fact jumping on the 64-bit ARM server bandwagon (http://www.amd.com/us/aboutamd/newsroom/Pages/presspage2012Oct29.aspx). My prediction that AMD is going to pull a Transmeta and deliver x86-on-ARM servers is looking quite probable now because you simply can't bet the farm on ARM without having some backward compatibility for running decades of existing legacy x86 software.
Lastly on the topic of small cores today, I recently ran across this page about a student project to implement a 32-bit MIPS processor on an FPGA:http://www.csupomona.edu/~dmpaulson/Processor32.html, what a cool hack!

Haswell's great leap forward
That all said, ARM and Atom for now trail the big-core devices by almost an order of magnitude (due to both clock speed differences and micro-architectural differences between big cores and small cores). For example, today those same builds of Bochs and Xformer running on ARM and Atom get trounced by a factor of 7x or more compared to my 4 GHz Ivy Bridge system - due to the roughly equal ratio of performance increase due to raw clock speed and out-of-order micro-architecture advantage.
Toward the end of my two-week Europe trip I was starting to crave the big-core "real" laptop experience to run big x86 apps like Visual Studio or watching a Bluray. The Sony VAIO I have, the F-series based on Sandy Bridge, comes with a Bluray drive, USB 3.0 ports, a nice large backlit keyboard, 4G connectivity, and yes, a real quad-core Sandy Bridge x86 processor. That's a true modern desktop replacement, while the Chromebook or Surface RT really only replace what we had 10 years ago with something smaller and lighter. I certainly do look forward to getting my hands one of the upcoming Haswell based Ultrabooks as a good middle ground - having something that is about the form factor of a tablet yet a real x86 computer that can run the development tools I use and that would even allow me to punt a lot of my existing big box systems.
Intel has been talking about Haswell since last year, posting the Haswell instruction set details to their web site early in 2012, and which I previously lectured about during my guest appearance at Conestoga College (the slides are here: http://www.emulators.com/docs/Rise-of-VMs.pdf). While it's been possible to experiment with Haswell instructions in Bochs and other simulators for a while, the Haswell hardware is now finally available to the public as of June and we can all now give the real thing a try.
I have been experimenting on my home-built Haswell system which cost me on the order of $500 in new parts (the Core i7-4770 CPU and ASUS Z87-PRO motherboard) and scavenged recycled parts from an existing Core i7 box (namely the power supply, case, SATA drives, and DDR3 memory). The 4770 runs at the same base clock speed of 3.4 GHz as the previous Sandy Bridge Core i7-2600 and Ivy Bridge Core i7-3770, so it is fairly easy to compare identical code on those three generations of Core i7 to measure improvements between generations.
Haswell docs (future 512-bit vectors!?!?)
Since people keep asking me where they can read up on Haswell technical details, here are some links to PDF files you should always have handy. There are three specific manuals I consult frequently, all of which are linked to on this main Intel documentation page:
http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
The first is Intel's x86 instruction set reference, which can be downloaded as a 7-volume set, a 3-volume set, and as a monolithic PDF file (which is the one I prefer, document #325462 at this link: http://download.intel.com/products/processor/manual/325462.pdf)
Next, Intel maintains a document which describes future instruction set extensions. For example, this is where the Haswell instructions were documented since last year before they were moved recently into the main document 325462. The future instruction set document is #319433 at this link: http://download-software.intel.com/sites/default/files/319433-015.pdf
It's a good idea to peek at these future instructions, whether you are a compiler developer, a kernel developer, or a virtual machine developer, it is your job to anticipate what new instructions and features you will soon have to add support for. No sooner had Haswell shipped, Intel updated the document last month to reveal future support for SHA1 hash instructions as well as 512-bit wide AVX operations ("AVX-512") and new register state called ZMM registers, the 512-bit wide extensions of 256-bit YMM and 128-bit XMM registers. In other words, do not assume AVX stops at 256 bit vectors. One hint that AVX would soon be getting widened is the fact that the AVX documentation referred to the register widths as "VL-1" (VL = vector length) rather than a hard-coded value of 256.
Finally, the third document I always keep handy is the Optimization Reference Manual, found here:http://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-optimization-manual.pdf. This document is great for learning about some of the new micro-architectural features that don't necessarily appear explicitly as new x86 instructions, such as the addition of the 4th ALU and zero-latency-moves.
Two versions of Haswell
One thing to note, the new desktop Haswell chips come in two varieties, the K versions and the non-K versions. With Sandy Bridge and Ivy Bridge, the "K" indicated that it was a clock multiplier unlocked device, great for over-clocking to levels of 4.2 GHz and even up to 5.1 GHz as I described in my posting last year. The non-K parts are what tend to appear in corporate desktops, where employees are not expected to be tweaking their systems.
With Haswell there is another significant distinction, which is exposed by looking at Intel's own processor comparison of the 4770 and 4770K parts:
- the 4770: http://ark.intel.com/products/75122
- the 4770K: http://ark.intel.com/products/75123
Why the Haswell critics are wrong
I've read a number of online reviews and comments from people who belly ache that Haswell is "only" 10% or 20% faster than Ivy Bridge. Oh boo hoo hoo, poor babies. Yes, if you just purchased an Ivy Bridge desktop system last year and mainly do email, web, and games, you probably don't need that minor performance boost. If peak performance of legacy code is what you are about and 10% doesn't do it for you, fine, keep over-clocking your Ivy Bridge.
However, if you are looking to purchase a new Ultrabook or tablet, you will absolute want Haswell over Ivy Bridge or Sandy Bridge devices. Each x86 core in Haswell is more power efficient, especially at idle, meaning longer battery life. Punt you old Core 2 laptop, it's time for Haswell.
As far as raw performance, I also disagree with some of the claims that Haswell delivers just marginal speedup. Even for legacy code (which is my term for any existing programs that run today on Core 2 or Atom which have obviously not been rewritten to take advantage of Haswell) I see surprisingly good performance increases. As I'd mentioned in my Sandy Bridge posting in Part 34, that generation delivered about a 15% to 25% boost in performance per clock cycle over the earlier Core 2 generation. In other words, the IPC (instructions per cycle) improved about 1.2x at the Sandy Bridge generation over the previous Core 2 and Core i7 Nehalem generations. While Ivy Bridge was mainly a die shrink and did not change x86 performance much, Haswell's new micro-architecture I've found can deliver an additional 25% IPC improvement over Sandy Bridge.
I have verified this in my own admittedly emulation related benchmark. Haswell delivers about 50% higher performance over the Core 2 processors at the same clock speed. This is why it's fantastic for mobile devices, as you can run Haswell at 33% lower clock speed than Core 2 to get the same level of x86 performance on legacy code, and lower clock speed translates to better battery life.
The way I think about the IPC improvements in Haswell is this: to equal the performance of say a 2.4 GHz Haswell core you'd need a 3.0 GHz Sandy Bridge core, a 3.6 GHz Core 2 core, or about a 9 GHz Pentium 4 / ARM / Atom core.
Haswell's new micro-architecture features
The last great monumental leap in Intel's x86 processors took place in 2006 with the releases of the Core and Core 2 micro-architectures to replace Pentium 4 for good. Core was effectively the desktop version of Pentium M, and both were based on the terrific Pentium Pro / Pentium II / Pentium III line of P6 micro-architectures. Core 2 added 64-bit support, as well as byte permutation capabilities in SSSE3 (which Atom also supports). Every one of my home desktop and cloud machines I use today - from my Mac Pro to my Thinkpad T500 and Sony VAIO laptops to my EC2 virtual machines to my Atom set top boxes - are all 64-bit processors supporting at least SSSE3 or higher running 64-bit Windows or Linux.
For the next 5 generations of Intel processors afterwards - 2008's Penryn, then Nehalem, Westmere, Sandy Bridge, and last year's Ivy Bridge - each introduced some minor incremental improvement such as SSE4 (which added things like CRC32 and POPCNT instructions), AES (for encryption), AVX (the 256-bit extensions for SSE floating point operations), and RDRAND (hardware random number generator).
What makes Haswell such a huge step forward is that it adds a comparable number of new features and improvements as those past 5 generations inone single generation! Haswell's bag of new tricks includes:
- HLE - Hardware Lock Elision, a backward compatible set of prefixes that can be applied to instructions such as LOCK CMPXCHG to minimize lock overhead under low contention
- RTM - Restricted Transactional Memory, the feature I've anticipated the most, the ability to atomically roll back a block of code or atomically commit a block of code
- BMI - Bit Manipulation Instructions, this is a set of about a dozen new 32-bit and 64-bit integer operations designed to perform Hacker's Delight type of bit manipulation instructions, bitfield operations, and flag-less shifts and multiplies. These are designed to accelerate encryption and handling of non-byte aligned data, such as processing bit vectors, decoding instructions, or performing bitfield moves.
- AVX2 - what SSE2 was to SSE, AVX2 is to AVX, adding 256-bit packed integer operations to the AVX instruction set
- FMA3 - Fused-Multiply-Add support permits common floating operations such as dot product and matrix multiply to execute multiply+add in one instruction
- a 4th ALU - up to 4 integer ALU operations can retire per clock cycle, leading to peak integer performance of over 14000 MIPS per core, definitely something that helps legacy code
- MOVBE - Move Big Endian load/store support, previously only available on the Atom, specifically helps to accelerate simulators of big endian machines such as 68040 and PowerPC.
- zero-latency register moves - common register-to-register move operations are handled by the register renamer instead of wasting an ALU operation, speeding up register calling convention
- 4K video support - the on-chip CPU is able to drive the new "4K" or UHD (Ultra High Definition) displays at 3840x2160 pixels, opening the door for much higher resolution laptops than the current glut of 1080p devices
The addition of the 4th ALU, zero-latency moves, and other micro-architectural tweaks are why clock-for-clock Haswell delivers the 10% to 25% faster IPC than Ivy Bridge for legacy code. That's an impressive improvement by itself, as what it really means is that Intel continued to find ways to extract even more instruction level parallelism (ILP) from existing legacy code. The addition of HLE, RTM, BMI, AVX2, FMA3, MOVBE instruction set extensions is a gold mine for compiler, OS, and virtual machine developers such as myself. Not since the addition of 64-bit mode to x86 has there been such a wealth of new instructions added all at once. As with the transition from 16-bit mode to 32-bit mode, or 32-bit mode to 64-bit mode, it will take a year or more native compilers, OSes, and virtual machines to fully take advantage of these six new features.
More on the details of these new features in future postings as I myself explore their full capabilities. There are already a lot of good documents and postings on Intel's web site such as this posting (http://software.intel.com/en-us/blogs/2011/06/13/haswell-new-instruction-descriptions-now-available/) so I'll just give a brief overview of some of the most interesting features.
The BMI instructions - scalar integer improvements
These have been a long time coming, finally adding parity to x86 with such instruction sets as 68020 and PowerPC as far as bit scan and bitfield operations. The ANDN (And Not) instruction for example is like the standard AND instruction but where the first source has its bits toggled. This operation already exists in SSE and AVX and is now available on plain scalar general purpose registers. ANDN is handy for mask and merge operations, for example when merging parts of two integers together in this fashion:
z = (a & mask) | (b & ~mask);
Normally in x86 one has to copy the mask to a temporary register, NOT it or XOR it with 1, and use that to AND with the value "b". With ANDN, the mask value can remain in a single register and this expression now compiles into just AND ANDN OR. This actually comes up in emulation code quite frequently. If you read my older posts on "lazy flags" evaluation, the lazy flags formulas actually involve an ANDN operation. I've modified my private Bochs 2.6.2 sources to now use this new instruction and verified that it actually does reduce the code sequence size of updating lazy flags.
Another set of BMI instructions improve on existing x86 instructions that previously had undefined results for arithmetic flags. This includes the newMULX, RORX, SARX, SHRX, SHLX instructions, which are "flagless" versions of the old MUL, ROR, SAR, SHR, SHL instruction in x86. Every AMD and Intel manual since the beginning of time has listed the arithmetic flags results of these instructions as being undefined. What that really means is that the EFLAGS bits are implementation dependent, on some generations a particular flag might be set to 0, on some to 1, and on some not modified. What this means for compilers and binary translators is less freedom to re-order instructions due to this unnecessary (yet useless) updating of the EFLAGS bits. By guaranteeing that the EFLAGS are not modified by these new instructions, not only do compilers have more freedom but the out-of-order pipeline itself has more freedom to re-order the instructions.
Similarly the new LZCNT and TZCNT instructions (Leading Zero Count and Trailing Zero Count) fix an undefined hole with the existing BSR and BSF(Bit Scan Reverse and Bit Scan Forward) instructions which did not define the result of an input value of zero. One of the things I really enjoyed about programming the PowerPC processor during Power Macintosh and Xbox 360 days was the extensive set of well-defined well-behaved bit twiddling operations on PowerPC. x86 now, finally after 20 years, brings parity with PowerPC in that respect.
That also means that x86 now finally has bitfield operations, something very relevant to emulation and simulation. Three new instructions, BEXTR(Bitfield Extract), PEXT (Parallel Extract), and PDEP (Parallel Deposit) bring the basic functionality of bitfield extraction and insertion to x86. These are roughly analogous to PowerPC's RLW* set of instructions for reading and storing into specific bitfields in a register. BMI takes things one step further by allowing a group of bitfields to be extracted or inserted (deposited as Intel calls it) in one instruction. The way this is done is that the PEXTand PDEP instructions do not take as sources a starting bit and bitfield width (as was done on 68040 and PowerPC). Instead, the second source to these instructions is a register containing a bitmask of the bits or extract from or deposit into. So if you want to pull out every sign bit from every nibble in an integer, you can. A single pair of PEXT PDEP instructions can be used to move an arbitrary bitfield from one register to another, even if at different bit positions (for example, C code like this: struct1.bf1 = struct2.bf2). This is extremely handy for decoding and encoding operationsthat operate on sub-byte granularity.
Finally, BMI is rounded out with a set of instructions that operate on the lowest set bit of an integer, BLSI (Extract Lowest Set Bit), BLSMSK (Get Mask Up To Lowest Set Bit), and BLSR (Reset Lowest Set Bit) which are shortcuts for Hacker's Delight style operations that reduce the need to copy to additional temporary registers.
Bochs 2.6.2
Just a quick tangent to reminder you all that the Bochs x86 simulator at http://bochs.sourceforge.net already supports emulation of the Haswell processor's BMI, AVX2, FMA3, and MOVBE instructions. You can start writing test code for Haswell and run it in Bochs even if you do not own a Haswell processor yet.
The official latest Bochs 2.6.2 release from May 2013 supports these, and if you sync to at least checkin #11721 from June 20, you also have the ability to specify the Haswell CPUID configuration in your bochsrc.txt file. I am currently synced to checkin #11733 for my Haswell experimentation. I find this to be a nice stable build from early July which I had no problem booting the Windows 8.1 Preview Release and latest releases of Ubuntu and Fedora Linux.
One last mention about Bochs and Windows today, there was a really great paper published at the SyScan 2013 conference this spring on the use of Bochs to find security holes in Windows. I champion the use of simulation as a debugging and code analysis tool, and this is a really fantastic and geeky read showing exactly how to do that with Bochs: http://j00ru.vexillium.org/?p=1695.
RTM and HLE - Transactional Memory
Back to Haswell's new hardware features. BMI is my second most anticipated set of extensions that Haswell brings but RTM (Restricted Transactional Memory) is what I'm really excited about and have been mentioning in talks and lectures for a few years now. What RTM essentially means is that you can execute a block of code atomically (or some number of blocks, the "R" for Restricted means that an upper bound to the size of the transaction). In older terminology, think of it as a form of MWCAS (Multi-Word Compare-And-Swap) - the ability to atomically update several integers in memory at arbitrary addresses. Since the beginning of x86 there has always been a limitation of atomically updating one address. Think of instructions such as LOCK INC, LOCK XADD, LOCK CMPXCHG8B, etc., these only can ever atomically read, modify, and store once at one address at a time. That's fine for atomically updating a single counter, updating a bit in a bit vector, or updating a simple hash table key-value pair, but is not adequate for more complex data structures such as inserting or deleting a node from a doubly linked list.
Traditionally, any time you need to do something complex and make it appear atomic you use a lock - some sort of operating system provided object such as a mutex or semaphore or critical section - which by itself is really just a flag that says "my thread owns this particular lock now". However, OS locks do not protect the data that you are really trying to protect and update atomically, they only protect the lock object! Any thread that does not similarly request and release the lock, or stomps directly on your data as you are modifying it, will lead to all sorts of common problems from hangs to crashes.
RTM is hardware enforced memory atomicity. It allows you to update multiple memory locations with the safety of knowing that either your updates will commit to memory atomically as seen by other cores, or if some other thread is trying to stomp on your data, your updates will get aborted and your thread is then notified that this conflict occurred.
At the instruction level RTM consists of only 4 new instructions: XBEGIN (Transaction Begin, which begins the atomic execution), XEND (Transaction End, which is really a "commit my data" operation), XABORT (Transaction Abort, which is explicitly undoing the transaction so far), and XTEST (Test if in a Transaction). If you write code which executes an XBEGIN, updates some memory, and then executes an XEND, if you make it past the XENDyour updates are guaranteed to have updated atomically as far as any other threads or cores are concerned. Should you choose to abort the transaction, or some conflict causes your transaction to end, your thread rolls back (the pipeline is flushed and any pending memory writes as well as register updates are punted) to the start of the transaction.
At the C/C++ source code level a transaction looks something like this (notice this is very similar structure to the old setjmp/longjmp paradigm where on failure the thread rolls back to the start and receives a different return value to indicate failure):
volatile long l; int fails = 0;This is a trivial example where a thread tries to atomically update a shared variable using a hardware transaction. In real code, you would either loop back and retry the transaction, or execute some fallback code. Even this trivial approach is great for doing things like testing the validity of a pointer. For example, you want to check if a memory address can be accessed or if it will throw an exception. Traditionally the way to test a bad address is to wrap the memory access in a __try/__except or try/catch block, but this causes a true hardware access violation, a context switching into the kernel mode to execute the OS'es exception handler, stack unwinding, and then a context switch back into user mode. This can cost thousands if not tens of thousands of clock cycles. With a transaction you know the result either way in a few hundred cycles. How? The return value of XBEGIN is a status code that distinguishes between success, an explicit XABORT, an atomicity conflict with another thread, or an exception. Testing on my Haswell system shows that a transaction ending with XABORT or access violation exception takes under 200 cycles, while normal successful transactions take as little as 50 cycles. Transactions therefore can be much faster than traditional page fault and memory protection mechanisms.
x = _xbegin(); // start the transaction, analogous to a setjmp()
if (x == _XBEGIN_STARTED)
{
l++; // something you want protected, like atomically increment a shared variable
_xend(); // commit the updated value
}
else
{
fails++; // fallback code, in this case just set a flag
}
Another advantage of transactions is that they reduce memory traffic. By not needing to actually "take a lock" as in my sample above, the frequent atomic updates of a shared lock variable are eliminated. This by the way is the premise of the HLE (Hardware Lock Elision) prefixes, which are a backward-compatible way to start and commit a transaction which appear to completely hide any update of the lock variable, thus "eliding the lock". This demonstrates another advantage of transactions - you are free to re-order memory accesses within a transaction in ways that violate the usual x86 memory ordering rules. For example, inside of a transaction you can make multiple updates to an array and just prior to committing the transaction check whether the array bounds have been exceeded (in which case you call xabort() to undo the transaction).
Transactions need not actually modify any memory, since an aborted transaction rolls back register state as well. Transactions could be used as a security feature to for example, stop a block of code from being interruptible, since any attempt to set breakpoints or halt the thread during a transaction will abort and roll back the transaction. Along those lines, some of the very security holes described in the SyScan 2013 paper mentioned above would have been avoided if recoded as Haswell RTM transactions.
With this brief description of RTM the astute reader should immediately realize the implications that transactional memory has for the world of emulation and virtualization and its potential to accelerate the performance of today's VM products - by a lot! I even firmly believe that Haswell opens the door to faster-than-real-time virtualization by allowing very aggressive optimizations on sandboxed code. That's all I will say for now (due to patents that I have pending or already issued on this topic) but here is some additional reading from Intel's site to start you thinking about transactional use cases:
http://software.intel.com/en-us/blogs/2012/02/07/coarse-grained-locks-and-transactional-synchronization-explained/
Chapter 14 of the monolithic Intel manual on Transactional Synchronization Extensions is also a good starting point.
Next time when I will give an update on my progress of the port of Gemulator and SoftMac to C++, an overview of happy new features in Windows 8.1 and Visual Studio 2013 that I find interesting, and report on my quest to score a 4K monitor. Happy computing!
August 25th Update!
One week later now I have gotten my hands on a 4K monitor, specifically this little beauty, the 39-inch SE39UY04 which is available on Amazon for the outrageous price of $699. I actually thought this was a typo at first, expecting a price in more the $5000 range, but no, the television truly does cost $699 delivered free with Amazon Prime. In hindsight, the 39-inch screen is roughly equivalent to 4 20-inch 1080p monitors, which these days have plummeted in price to under $100, so it's plausible that manufacturing yield and cost of cutting a piece of LCD twice as wide and twice as tall is not exponentially outrageous anymore.
The television/monitor (the television portion is fairly rudimentary, this is for all intents and purposes a sweet monitor) arrived with a stand and HDMI cable. There are 3 HDMI inputs, so I connected the cable first to my laptop, which rendered a maximum 1920x1080 60 Hz image, the same crappy 1080p experience that computer and monitor manufacturers have boxed us into over the past few years.
By the way I have to digress. Isn't it interesting that 10 years ago I was able to purchase a Dell D800 laptop that included a built-in 1920x1200 screen, and yet these days just about every piece of junk laptop and desktop monitor is hardcoded to 1920x1080. We don't all watch television or Bluray all the time, some of us actually use our computers to write code. I hate 1080p and since 2006 the way I have worked around this limitation is to use an Apple 30-inch cinema display and more recently a very sweet Dell 30-inch U3011. That Dell monitor, which I purchased for about $1100 last year and which still sells for about that price, would seem to set a bar that no 30-inch or larger monitor, or 2560x1600 or larger monitor could sell for under $1100, yet this is actually the case with the Seiki.
Anyway, back to quest for 4K. I then connected my Haswell box to the monitor, plugging the HDMI cable into the HDMI port of the nVidia video card. Still no dice, 1920x1080. I then realized I needed to actually use the HDMI output coming directly off the motherboard, the output from the Haswell itself. That worked! 3840x2160 at 30 Hz.
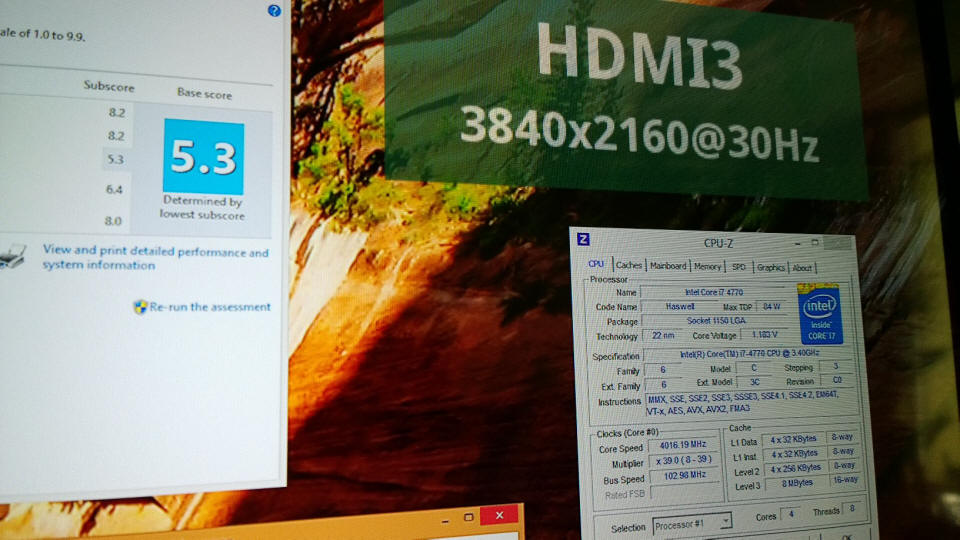
The slower frame rate is necessary due to the bandwidth limitations of HDMI. While DVI and HDMI can drive the 2560x1600 displays of the Apple and Dell monitors just fine at 60 Hz, a resolution of 3840x2160 contains 2.02x the number of pixels, and thus necessitates cutting the frame rate in half. The output is still beautiful, and Windows 8 has no problem rendering a gorgeous looking 3840x2160 desktop. Look at those wee little icons :-)
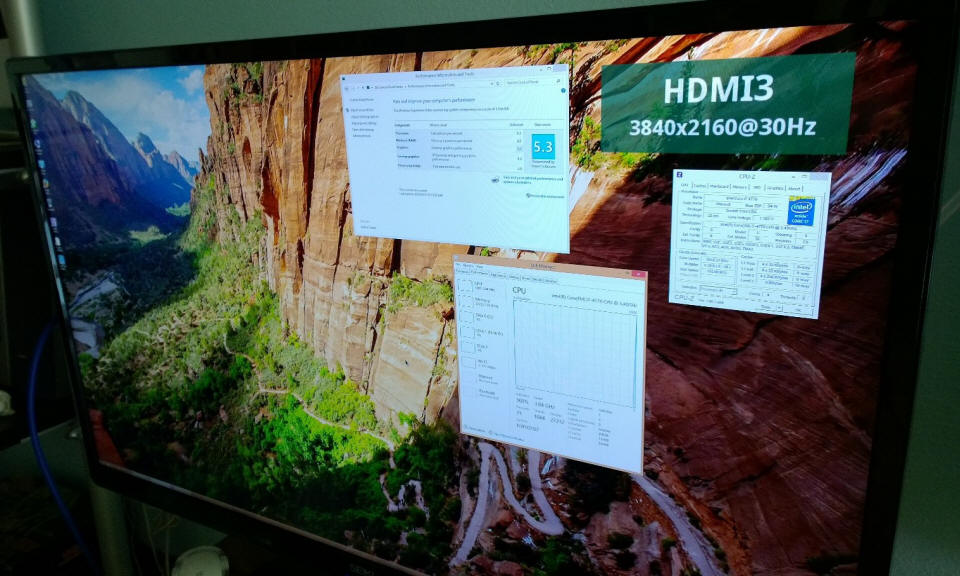
I can happily say if this is what the first generation of 4K monitors costs and looks like, the days of crappy 1080p are soon over!
[Part 36] [Table Of Contents] [Return to Emulators.com]
Comments
Post a Comment